Navigating Corporate Filings
Information Extraction via (Seek)Edgar
Dr. Mingze Gao
Department of Applied Finance; Macquarie University FinTech and Banking Research Centre
2026-04-23
Why filings, why now
A public archive of firm behaviour
Firms disclose strategy, risks, transactions, ownership, governance, contracts, and financials.
These disclosures are:
- Public: no proprietary access required for core EDGAR data.
- Time-stamped: filing dates can be linked to outcomes.
- Rich: text, tables, XBRL, exhibits, signatures, and metadata.
- Legally consequential: made under regulatory obligation.
The key opportunity is not just reading filings. It is converting disclosure into research variables.
Not only for finance and accounting
A filing can be read as:
- a legal document,
- a financial report,
- a strategy document, or
- a text corpus.
So filings speak to many fields:
- Strategy: competitive positioning, restructuring, market entry.
- Management: leadership, governance, incentives.
- Innovation / IS: AI, cybersecurity, data governance.
- Marketing: customers, channels, product risk, brand incidents.
- Entrepreneurship: IPOs, founder control, venture exits.
- Political economy: regulation, sanctions, geopolitical exposure.
EDGAR by the numbers
Filings
49.7M+
filings on EDGAR, 1994–2025.
Filers
943k+
unique filer identifiers (CIKs).
Annual pace
~2 million
filings received per year since 2004.
Every business day
~8,000
new filings land on EDGAR on a typical business day.
Searches
~24 billion
online searches of EDGAR per year (FY 2025).
Coverage
Since 1993
mandatory electronic filing phased in 1993–1996.
Counts computed from the SEC EDGAR full-index. Search volume from the SEC FY 2025 Congressional Budget Justification.
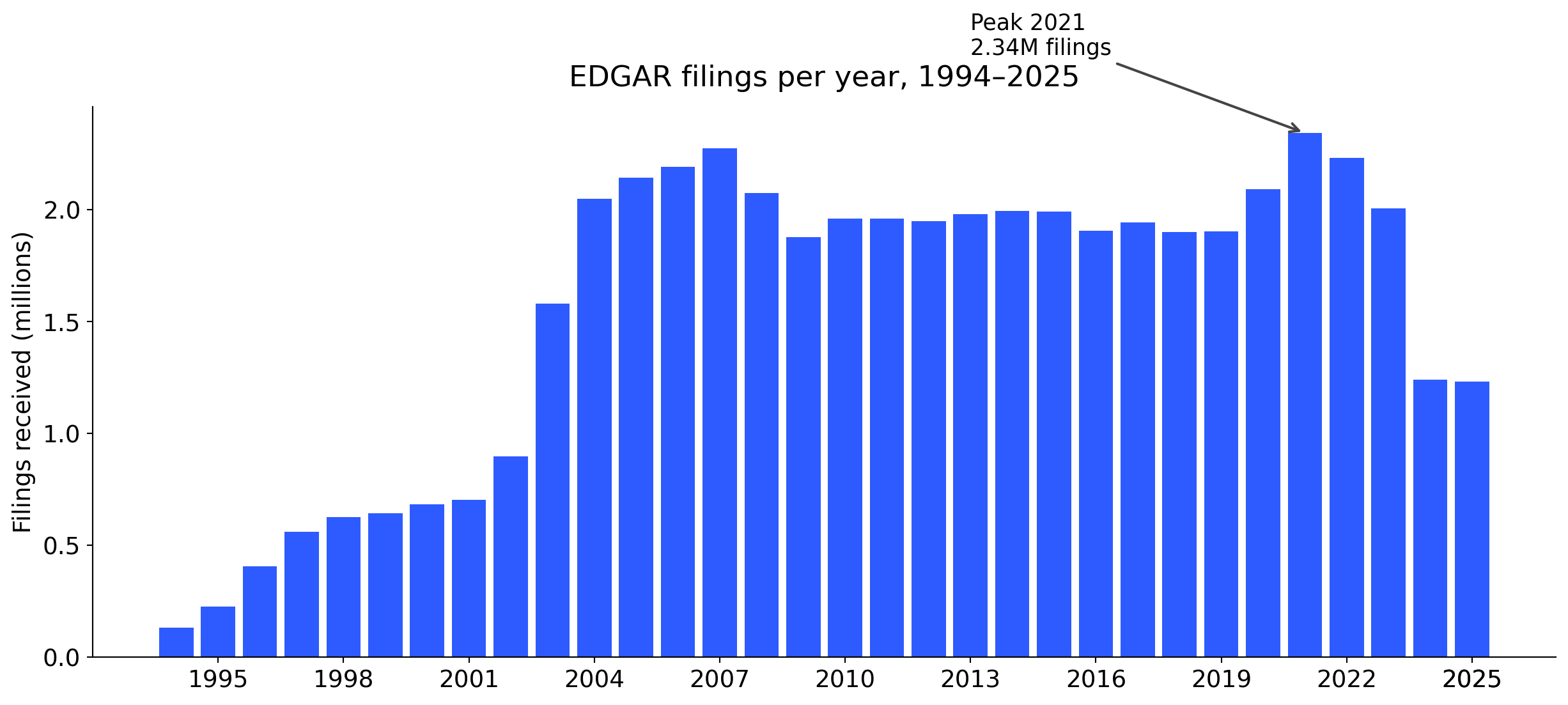
Three decades of growth
The step-up in 2003–2004 reflects widening 8-K triggers and expanded ownership-reporting rules. Each regulatory change leaves a fingerprint in the data.
Beyond the forms you already know
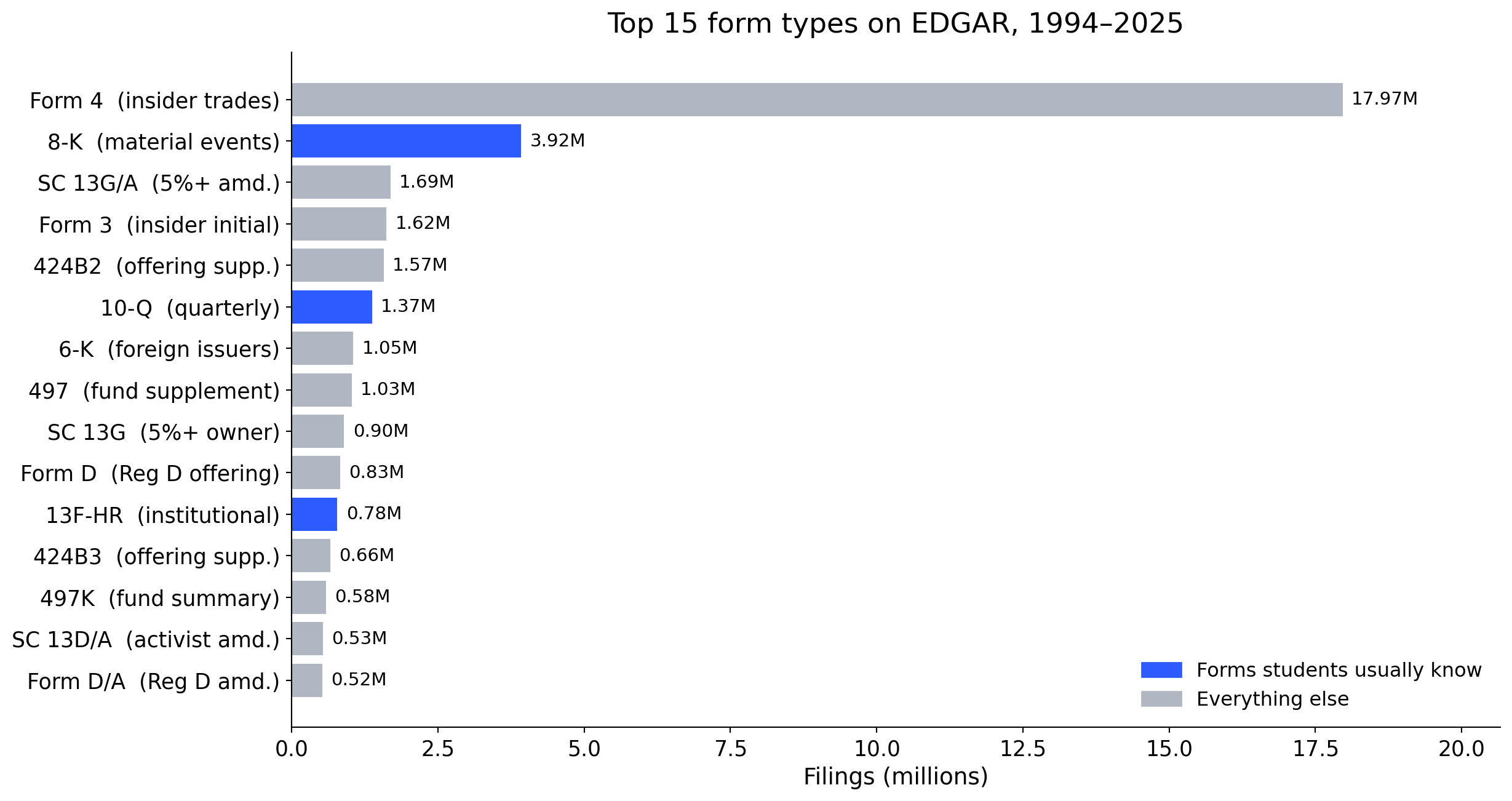
Only 4 of the top 15 forms are part of the standard MBA / finance curriculum. Most research variables live in the grey bars.
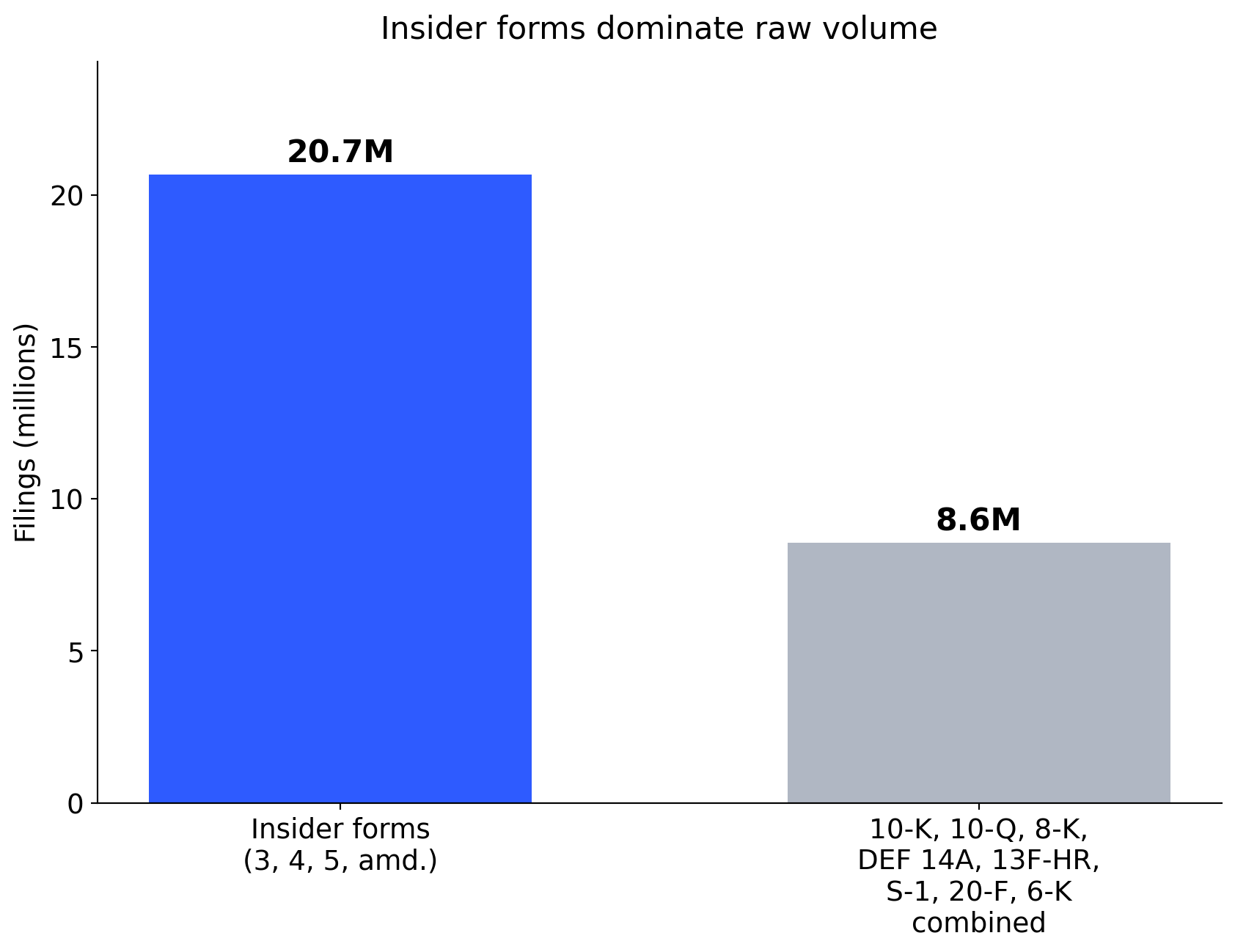
The most-filed form you probably haven’t heard of
Form 4 is a one-page filing that an officer, director, or 10% shareholder submits within two business days of trading their company’s shares.
- 17.9 million Form 4 filings since 1994.
- More than 10-K, 10-Q, and 8-K combined.
- Each filing reveals who traded, how much, at what price, when.
Research idea
Do insiders sell systematically before negative news? Do director purchases signal board confidence? Form 4 gives you the raw material.
Who files the most? (not who you think)
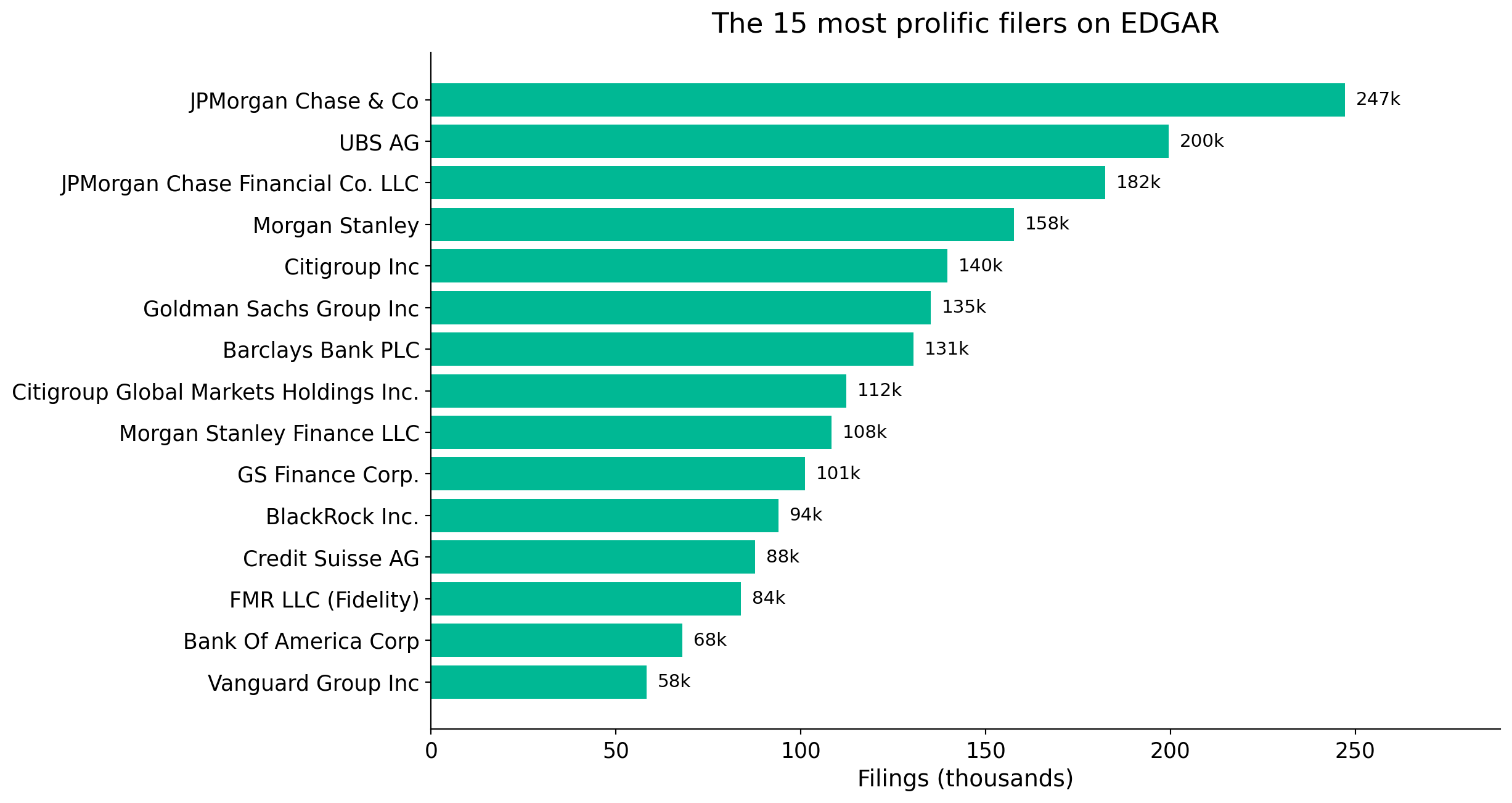
Not Apple. Not Tesla. The most prolific filers are investment banks, asset managers, and their structured-product issuing vehicles submitting thousands of offering supplements and ownership reports. The “firm” in your data is not always the “firm” in your theory.
Filings grouped by research use
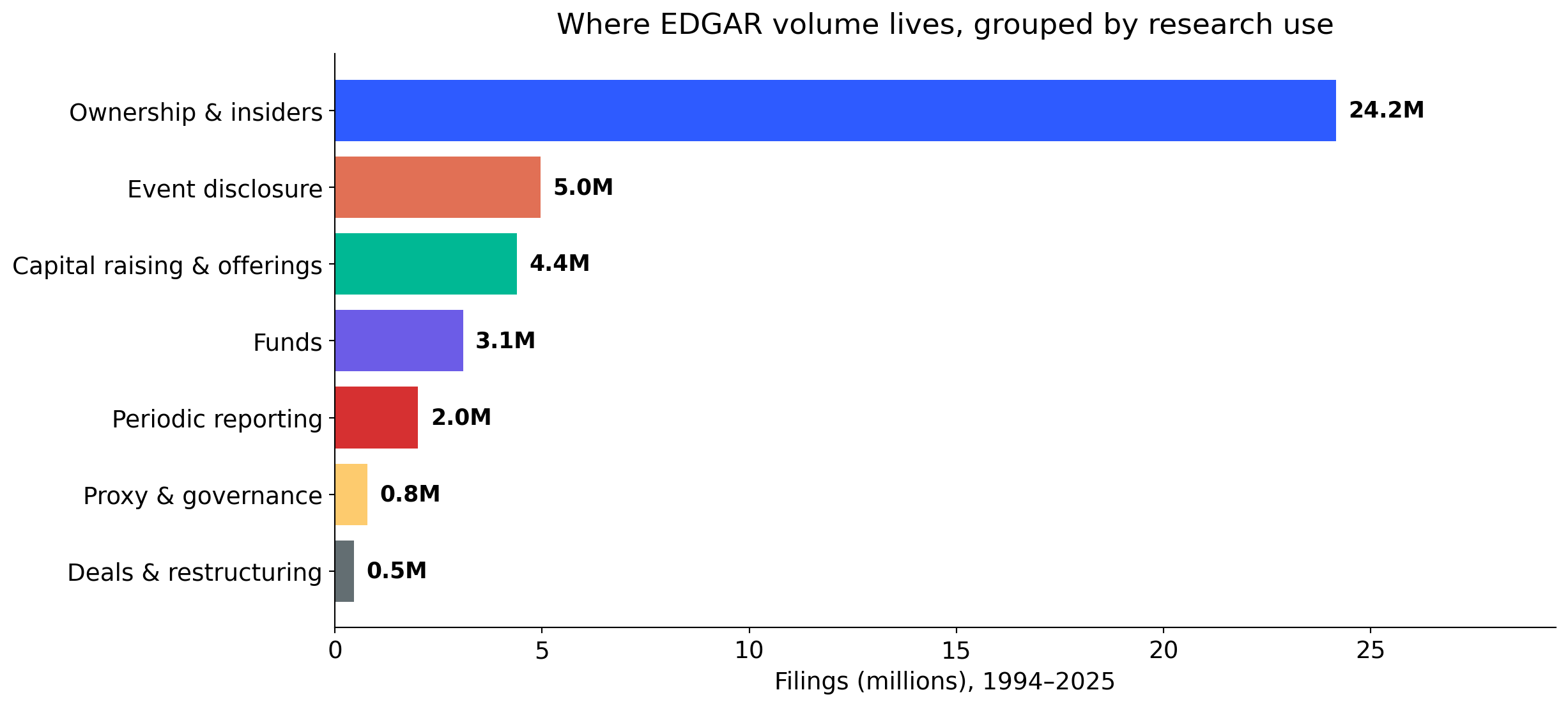
Periodic 10-K / 10-Q filings are a small share of EDGAR volume. The archive is far broader than the forms we teach first.
What makes filings distinctive
Breadth
One archive covers listings, ownership, governance, material events, capital raising, deals, and contracts.
Longitudinal depth
Many firms have decades of filings, enabling within-firm designs.
Granularity
Items, sections, tables, XBRL tags, exhibits, signatures. Each layer supports a different empirical question.
Accountability
Disclosures are legally consequential. This is why they are often more careful, more consistent, and more comparable than press releases or pitch decks.
Filings are imperfect, strategic, and sometimes boilerplate. But those features can themselves become research objects.
1. The filing ecosystem
EDGAR in one slide
EDGAR: Electronic Data Gathering, Analysis, and Retrieval.
- SEC’s primary electronic submission and public access system.
- Includes company filings, individual ownership filings, fund filings, exhibits, and metadata.
- Public access through web search, company pages, full-text search, and APIs.
“SEC filings” is a shorthand. The set also includes registration statements, proxy materials, insider filings, fund filings, and exhibits. Each has a different research purpose.
A map of the filing universe
Stop thinking in form codes. Think in research use.
Periodic reporting
- 10-K, 10-Q, 20-F, 40-F
Event disclosure
- 8-K, 6-K
Ownership and trading
- 13D, 13G, 13F, Forms 3, 4, 5
Governance and shareholder process
- DEF 14A, DEFA14A, PRE 14A
Capital raising and listing
- S-1, F-1, S-3, prospectuses
Deals and restructuring
- S-4, merger proxy, tender offers
Exhibits
- EX-10 credit agreements, EX-2 merger agreements, employment contracts, charters, bylaws
The form is only the starting point. The research variable may live in an item, a table, or an exhibit.
Periodic reports
The recurring narrative of the firm.
Standard sections (10-K):
- Business description, risk factors, MD&A.
- Financial statements and footnotes.
- Segment and geographic discussion.
- Controls, legal proceedings, management certification.
Things researchers have measured:
- Cybersecurity risk language.
- AI adoption and strategic orientation.
- Customer concentration.
- Climate and supply-chain exposure.
- Footnote complexity and accounting estimates.
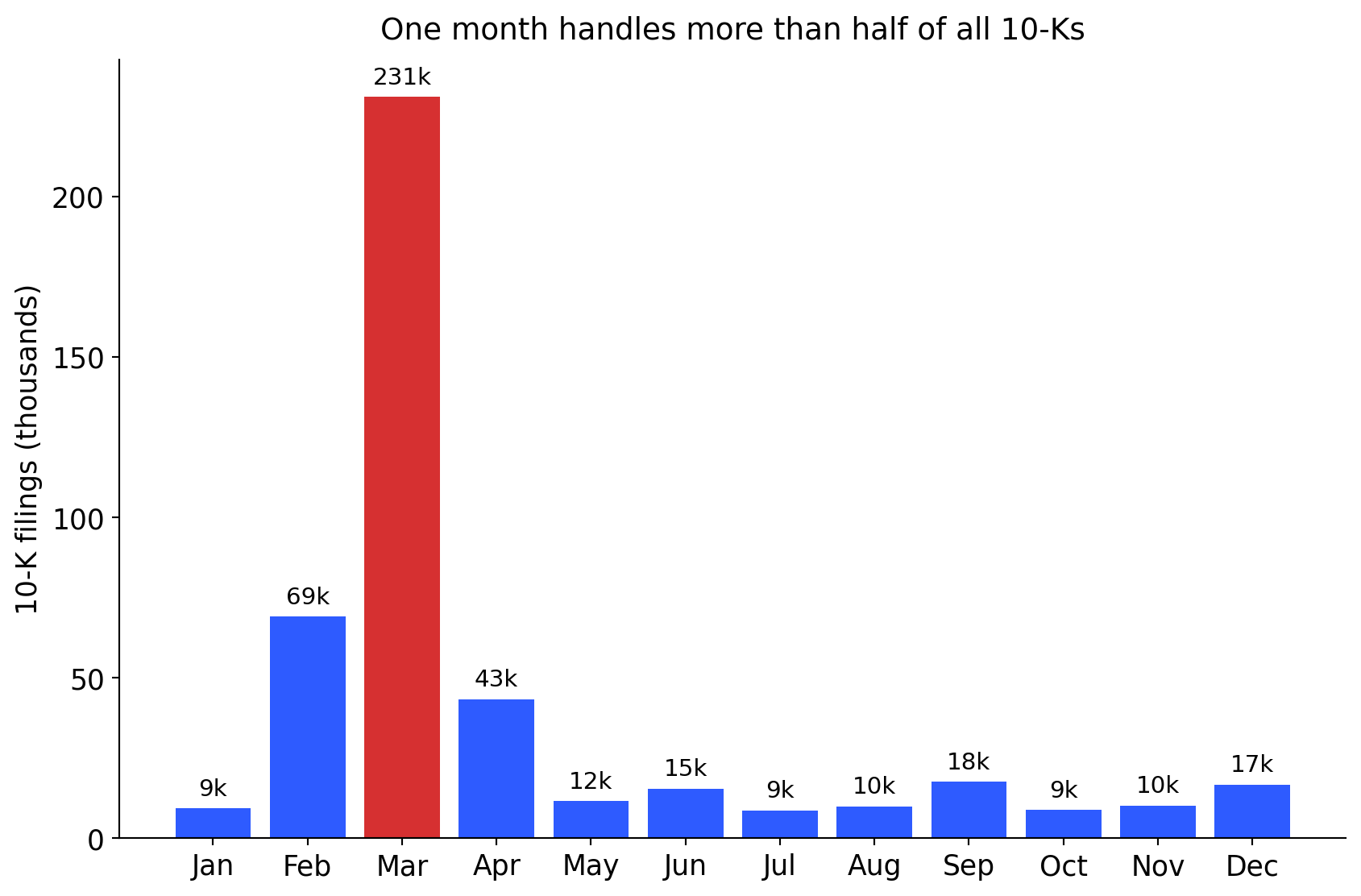
Most U.S. firms have a December fiscal year-end. Large filers must submit their 10-K within 60 days, others within 75–90 days. The calendar shapes the data.
Event-driven filings
When something material happens.
8-K can report:
- Material agreements, impairments, restatements.
- Leadership changes, auditor changes.
- Results announcements, financing events, acquisitions.
6-K transmits material information disclosed by foreign issuers abroad.
Research idea
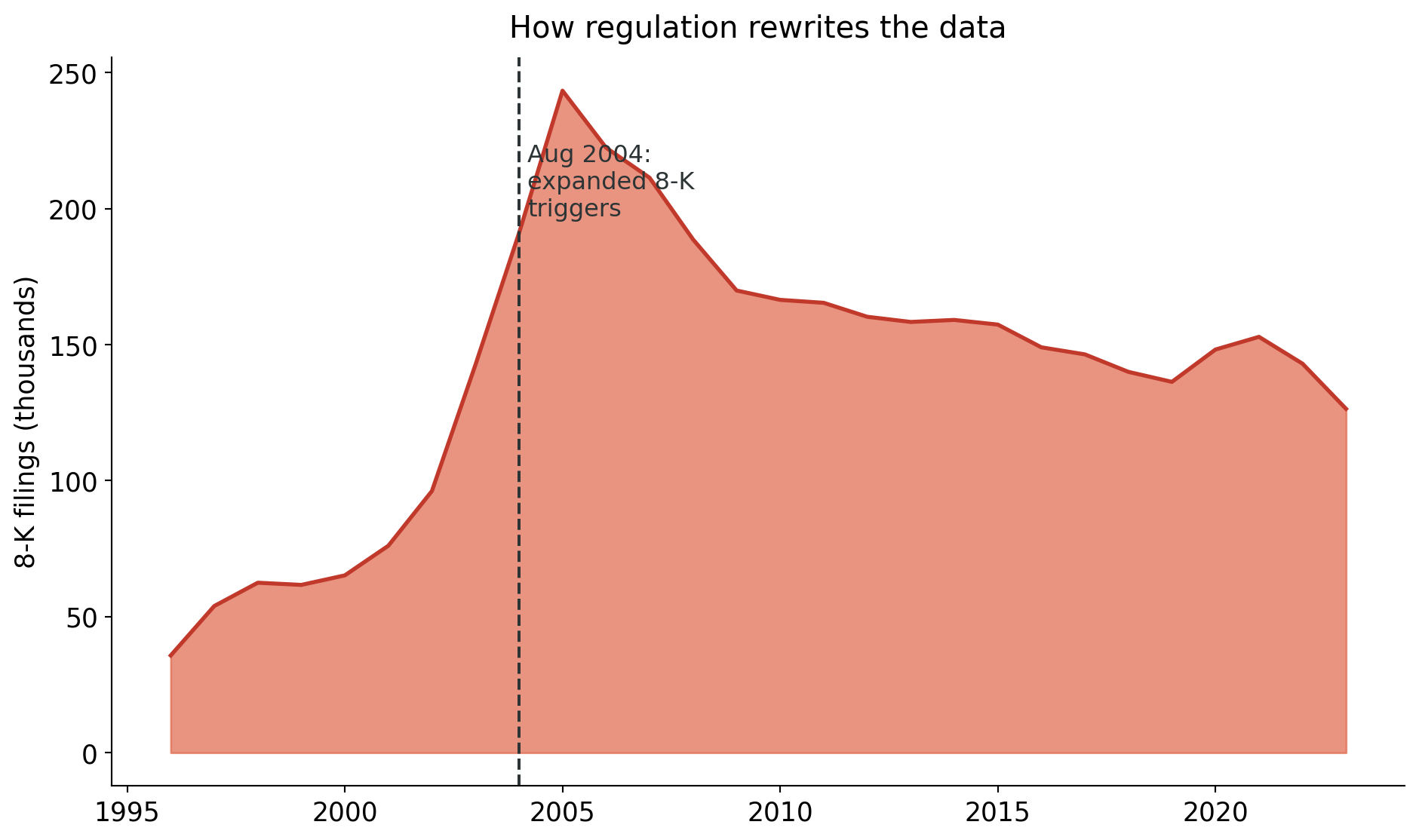
Teaching moment: the SEC’s 2004 rule change more than doubled 8-K volume. Rule changes and data go together.
Ownership, trading, and influence
- 13F: institutional holdings (quarterly).
- 13D / 13G: beneficial ownership, activism, large stakes.
- Forms 3, 4, 5: insider holdings and transactions.
Used to study:
- Governance and monitoring.
- Informed trading and insider behaviour.
- Activism and investor coalitions.
13F has reporting thresholds and covers only certain managers and securities. Do not treat it as the complete institutional portfolio.
Proxies: boards, pay, voting
DEF 14A is a dense data source in itself.
Three panels inside one proxy:
- People: director background, independence, tenure.
- Pay: executive compensation tables and CD&A.
- Votes: proposals, say-on-pay, shareholder proposals.
Research idea
A single DEF 14A can yield director-level, executive-level, and proposal-level panels. Link these to outcomes in periodic filings to study governance mechanisms. The entire E-index literature (Bebchuk et al. 2009) started from proxy reading.
Registration statements
Firms telling their story to investors.
- S-1, F-1: IPOs and foreign issuers.
- S-3 and prospectuses: seasoned offerings.
Why this matters for research:
- Rich textual information exists before public trading history.
- Founder control, lock-ups, and risk narratives are disclosed here.
- Useful for entrepreneurship, innovation, and capital-market research.
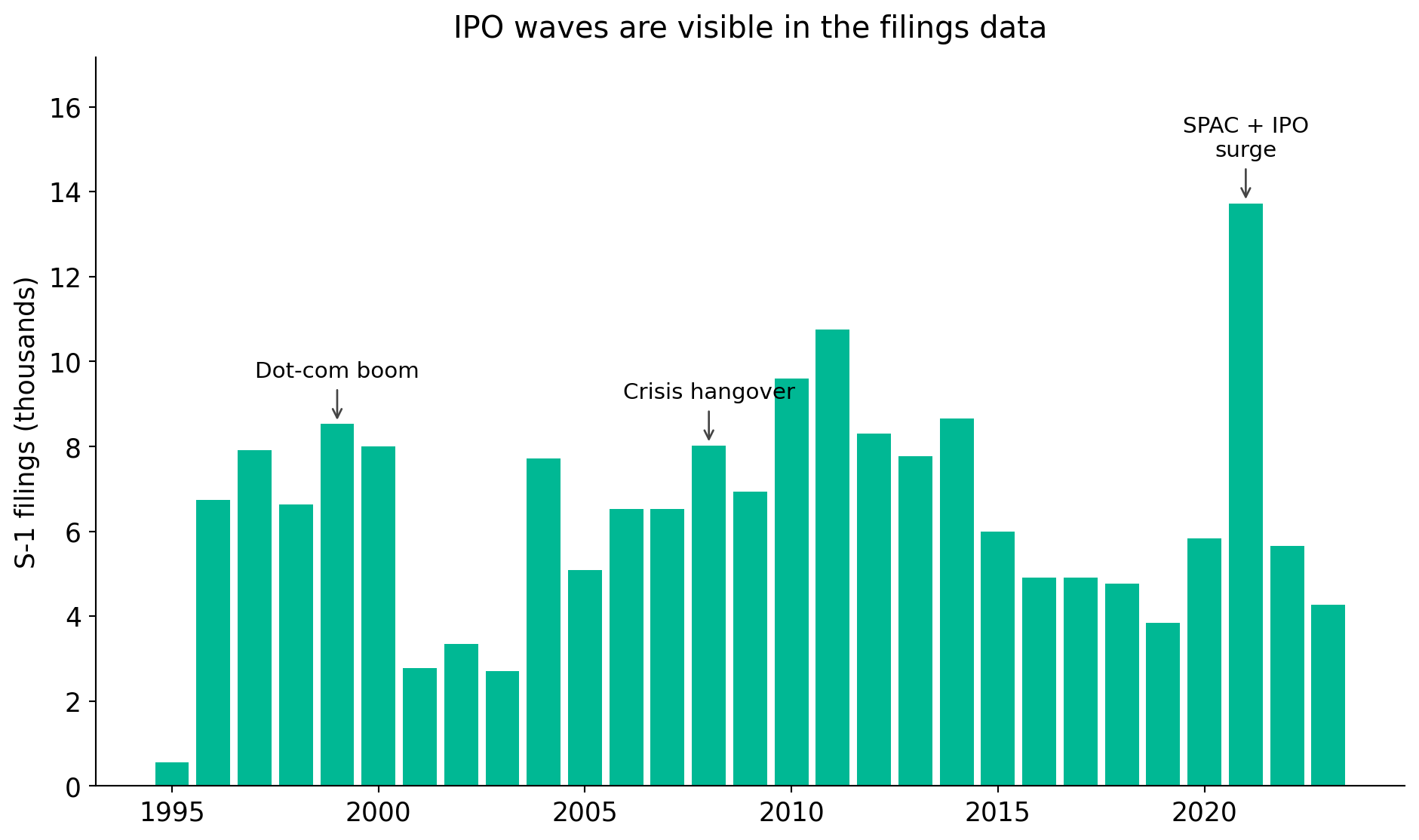
Market history is written in these filings. Dot-com (1999–2000), the post-crisis freeze (2008–2009), and the 2021 SPAC / IPO wave all show up as bumps in the S-1 series.
Exhibits are the hidden goldmine
Most students stop at the main filing. Much of the richest data is attached.
Exhibits can contain:
- Credit agreements (EX-10) with covenants, pricing, collateral.
- Acquisition agreements (EX-2) with representations and break fees.
- Employment contracts with pay and severance structures.
- Charters, bylaws, underwriting agreements, supply contracts.
For many research questions, the exhibit is the dataset.
2. What research can filings enable
One archive, many questions
| Discipline | Filing object | Example idea |
|---|---|---|
| Finance | EX-10 credit agreements | Contract terms and investment |
| Accounting | 10-K footnotes | Estimates and reporting quality |
| Management | DEF 14A | Board structure and strategy |
| IS | 10-K risk factors | Cyber and AI risk disclosure |
| Discipline | Filing object | Example idea |
|---|---|---|
| Entrepreneurship | S-1 / F-1 | Founder control and IPO outcomes |
| Marketing | 10-K business sections | Customer concentration and value |
| IB | 20-F / 6-K | Geopolitical and regulatory exposure |
| Political economy | 8-K, DEF 14A | Regulation and corporate response |
Pick a construct you care about. Then ask: which filing would be required to disclose it?
What researchers have already built from filings
The literature has turned EDGAR into a source of original constructs, treatments, and panels. Four overlapping waves.
I. Text as data. Two decades of measuring language.
II. Events as treatments. Dated disclosures as empirical experiments.
III. Ownership and influence. Who holds, who trades, who votes.
IV. Pulling new constructs from text. Risk, strategy, and technology measured at the firm-year.
The point is not to replicate these papers. It is to recognise that every wave opened new variables for fields far beyond where they started. Your dissertation can do the same.
Wave I: text as data
From readability to sentiment to firm networks.
- Li (2008) showed that harder-to-read 10-Ks predict lower earnings persistence. One variable from text, one result.
- Loughran and McDonald (2011) built finance-tuned sentiment dictionaries after showing off-the-shelf tools misread filings. Now standard.
- Hoberg and Phillips (2016) constructed text-based industry networks from 10-K product descriptions. A strategy paper, built entirely from filings.
- Cohen et al. (2020) showed that firms that change their 10-K language earn measurably different future returns.
- Loughran and McDonald (2016) surveys the whole field.
For any field
- Management: how firms describe competitors, strategy, capabilities.
- IS / innovation: how firms describe technology adoption.
- Marketing: how firms describe customers, channels, brand risk.
- Entrepreneurship: how IPO firms frame their story.
The methods started in finance and accounting. The applications are open in every business discipline.
Wave II: events as treatments
Dated disclosures support clean empirical designs.
- Lerman and Livnat (2010) studied how the SEC’s 2004 expansion of 8-K triggers changed what firms disclose and how markets respond. Rule change as natural experiment.
- Amir et al. (2018) used disclosure gaps to ask whether firms underreport cyber-attacks. Absence of disclosure is itself a variable.
- Florackis et al. (2023) built a firm-level cyber-risk measure from 10-K risk factors and linked it to returns.
- Brav et al. (2008) used the Schedule 13D filing as the event stamp for hedge-fund activism. A governance paper built from a filing.
Research idea
After a major regulation (climate rule, AI rule, cyber rule, human-capital rule), firms must say something new. That rule change is the event. That new language is the data.
Wave III: ownership and influence
Who holds, who trades, who votes.
- Brav et al. (2008): hedge-fund activism via 13D filings shifts governance and performance.
- Bebchuk et al. (2009): six governance provisions (E-index) extracted from proxies predict firm value.
- Edmans et al. (2013): stock liquidity shapes blockholder governance, measured from 13D-to-13G switches.
- Edmans (2014) and Yermack (2010) survey the field.
For any field
- Management: how institutional holders shape operating and HR decisions.
- Strategy: how activist pressure changes acquisitions and divestitures.
- Political economy: how voting patterns respond to regulatory shocks.
- Entrepreneurship: how founder and VC stakes evolve after IPO.
Wave IV: new measures from filing text
Purpose-built firm-level variables that did not exist ten years ago.
- Hassan et al. (2019) built firm-level political risk from earnings-call and filing text. Now used across economics, political economy, and strategy.
- Sautner et al. (2023) built firm-level climate-change exposure measures, widely adopted in sustainability and finance research.
- Babina et al. (2024) measured AI investment from filings and links to firm growth and product innovation.
- Matsumura et al. (2014) showed carbon disclosures change firm value.
- Patatoukas (2012) turned customer-concentration disclosures into a marketing / strategy variable.
Why this matters for you
Each of these measures did not exist before someone went into filings and built it. The next firm-level measure is waiting for someone in your cohort to construct it.
Research idea
What construct does your field care about that is not in Compustat, WRDS, or any proprietary database? There is a good chance firms already disclose it somewhere.
Case study: loan contracts as research data
Question
Does the quality of lender screening shape M&A performance?
Data challenge
Detailed loan contract terms are not in standard databases.
Filing opportunity
Loan agreements are disclosed as exhibits to 8-Ks, 10-Ks, and 10-Qs.
Design
Hand-collect loan agreements, link to syndicated loan data, then link to M&A deals.
The broader lesson
- Filings reveal mechanisms, not just outcomes.
- Hand collection stays valuable when the key variable is not in commercial data.
- Contracts connect banking, law, governance, and corporate investment.
- A good filing-based project usually starts with a small manual pilot.
Practical rule
A strong filing project often begins with reading twenty filings very carefully.
Text is data, but not automatically good data
Narrative sections that researchers commonly use:
- Risk factors, MD&A, business descriptions.
- Legal proceedings, footnotes, auditor language.
- Climate and sustainability language.
- AI, cybersecurity, privacy, supply chain, sanctions, geopolitical risk.
What text can measure:
- Exposure, attention, concern, complexity, strategic orientation, response to regulation.
Boilerplate language is not automatically noise. Sometimes the template itself is the object of interest. Sometimes a deviation from the template is. Cohen et al. (2020) built an entire return-predictability paper out of how firms change their 10-K language year over year.
Governance and influence: example questions
From ownership and proxy data:
- Do activist threats reshape disclosure?
- Do insider trades precede strategic announcements?
- Do institutional holders influence innovation or ESG strategy?
- Does board composition affect AI / cyber risk governance?
Innovation, AI, and cyber risk
Firms discuss technology in business descriptions, risk factors, MD&A, and sometimes 8-Ks.
Possible research angles:
- Adoption: who is investing in AI and how.
- Risk: cybersecurity incident disclosure and its consequences.
- Strategy: hype, capability, or genuine differentiation.
- Governance: board and committee oversight of emerging risks.
Do not treat every mention of “AI” as adoption. Start with careful validation.
Foreign issuers and comparative work
Beyond U.S. domestic firms.
- 20-F: annual reports for foreign private issuers.
- 6-K: current reports, often transmitting home-market disclosures.
Useful for:
- Cross-listing and international strategy.
- Regulatory exposure and geopolitical risk.
- Comparative disclosure quality.
Comparability is not automatic. Rule differences, audit regimes, and language translation all shape what can be measured.
3. From idea to data
The practical workflow
- Define the construct.
- Identify the likely filing family.
- Manually inspect filings.
- Write an extraction protocol.
- Pilot and validate.
- Scale the download.
- Link to outcomes.
- Document every decision.
Do not automate before you understand what the relevant disclosure actually looks like.
The point of the pilot is not to build the final dataset. It is to prove that the signal exists and that you can recognise it reliably.
A filing is not one object
Think of each filing as layered.
| Layer | What it contains | Typical extraction |
|---|---|---|
| Metadata | CIK, accession, form, filing date | API / index |
| Sections | Items, MD&A, risk factors | HTML parsing |
| Tables | Compensation, financials, ownership | Table parsing |
| XBRL | Structured accounting facts | XBRL API |
| Text | Narratives, footnotes | NLP / LLM |
| Exhibits | Contracts, agreements, charters | Exhibit indexes |
Different layers require different extraction methods. Matching the layer to the method is the core of a sound pipeline.
Search first, scale later
Start in the browser, not in Python.
EDGAR offers:
- Company search and full-text search.
- Filters by date, company, person, form type, and location.
- Full-text search since 2001 for electronic filings.
Try phrases that should reveal the mechanism:
- “credit agreement”, “material adverse change”
- “artificial intelligence”, “cybersecurity incident”
- “customer concentration”, “going concern”
Read the first twenty results carefully. What is a true positive? What is a false positive? Write it down.
EDGAR, SEC APIs, SeekEdgar, Python
Match the tool to the stage of the project.
| Tool | Best for | Watch out for |
|---|---|---|
| EDGAR web search | Official access, browsing, full-text search | Manual pace |
| SEC APIs | Reproducible downloads, submissions, XBRL | Careful request handling |
| SeekEdgar | Exploratory search, no-code extraction, tables, footnotes, MD&A | Access and subscription |
| Python | Flexible, reproducible pipelines | Validation and maintenance |
Exploration and production are different tasks. It is normal to use different tools for each.
A minimal Python example
From CIK to filing metadata.
Code
import requests
import pandas as pd
headers = {
"User-Agent": "Your Name your.email@example.com"
}
cik = "0000320193" # Apple Inc.
url = f"https://data.sec.gov/submissions/CIK{cik}.json"
data = requests.get(url, headers=headers, timeout=30).json()
recent = pd.DataFrame(data["filings"]["recent"])
recent[["form", "filingDate", "accessionNumber", "primaryDocument"]].head(10)Always include a real User-Agent with contact details when making scripted SEC requests. Be patient with request rates.
The extraction ladder
From simple to complex, pick the lowest rung that works.
- Manual coding.
- Keyword screening.
- Regular expressions.
- HTML parsing.
- XBRL facts.
- NLP classification.
- LLM-assisted extraction.
- Human validation at every level.
Higher complexity is not always better. A validated keyword rule can outperform a black-box classifier for a well-defined construct.
Validation is the research design
If you cannot defend the extraction, you cannot defend the paper.
Minimum practice:
- Randomly sample extracted observations.
- Track false positives and false negatives.
- Hand-code a reference subset.
- Record ambiguous cases and how they were resolved.
- Predefine coding rules. Report them.
The most common weakness in filing-based research is not access. It is unvalidated extraction.
4. Pitfalls and what to do about them
Common pitfalls and fixes
| Pitfall | Fix |
|---|---|
| Treating form type as content | Inspect items, sections, and exhibits |
| Confusing filing date and event date | Extract both and justify timing |
| Ignoring amendments | Track /A filings and restatements |
| Ignoring exhibits | Search exhibit indexes explicitly |
| Overusing keywords | Validate semantic meaning |
| Assuming comparability over time | Account for rule changes and templates |
| Undocumented parsing | Build a reproducible protocol |
| LLM extraction without audit | Use human validation samples |
Responsible use of public filings
Public does not mean effortless.
- Respect SEC access policies and rate limits.
- Include contact details in scripted requests.
- Avoid unnecessary repeated downloads.
- Cache locally. Do not re-scrape what you already have.
- Preserve reproducibility.
- Do not infer sensitive individual-level claims beyond what the filing supports.
Good filing research looks like good archival research. The archive is large, but the discipline is the same: document, validate, attribute.
How to start this month
A four-step starter plan.
- Pick one construct you cannot easily observe in standard datasets.
- Identify two or three likely filing families.
- Read twenty filings manually.
- Build a small extraction and validation table.
The goal of the first week is not a full dataset. It is to prove that the signal exists and that you can detect it reliably.
Start with a research question, not a form code
- What do firms do that is hard to observe elsewhere?
- Which disclosure would be required to reveal it?
- Can you validate the signal in twenty filings?
- Can you scale it responsibly?
Corporate filings are not just documents to read. They are empirical traces of firm behaviour.
Appendix
A1. Links and resources
- SEC EDGAR full-text search: sec.gov/edgar/search
- SEC company browsing: sec.gov/edgar/browse
- SEC developer resources: sec.gov/about/developer-resources
- SEC EDGAR APIs: sec.gov/search-filings/edgar-application-programming-interfaces
- Accessing EDGAR data: sec.gov/search-filings/edgar-search-assistance/accessing-edgar-data
- Presenter’s note on SEC textual analysis: mingze-gao.com/posts/textual-analysis-on-sec-filings
- SeekEdgar: seekedgar.com
A2. Common filing families
| Family | Examples | Typical research use |
|---|---|---|
| Periodic reports | 10-K, 10-Q, 20-F, 40-F | Business, risks, financials, MD&A |
| Current reports | 8-K, 6-K | Events, agreements, management changes |
| Ownership | 13D, 13G, 13F, Forms 3/4/5 | Ownership, activism, insider trades |
| Proxy | DEF 14A, PRE 14A | Boards, pay, votes, proposals |
| Registration | S-1, F-1, S-3 | IPOs, offerings, narratives |
| Deals | S-4, merger proxy, tender offers | M&A, restructuring, control |
| Exhibits | EX-2, EX-3, EX-10 | Contracts, charters, material agreements |
A3. SEC API endpoints
Core structured endpoints:
- Company submissions:
https://data.sec.gov/submissions/CIK##########.json - Company facts:
https://data.sec.gov/api/xbrl/companyfacts/CIK##########.json - Company concept:
https://data.sec.gov/api/xbrl/companyconcept/CIK##########/us-gaap/<Tag>.json - Frames:
https://data.sec.gov/api/xbrl/frames/us-gaap/<Tag>/USD/CY2019Q1I.json
Two practical rules:
- CIK must be zero-padded to 10 digits.
- Always send a proper User-Agent with contact information.
A4. Python: construct an archive URL
The primary document filename comes from the submissions JSON. Do not hard-code filenames unless verified against the index.
A5. From search terms to a validation table
A protocol template that travels well across disciplines.
| Field | Definition | Source | Extraction rule | Validation |
|---|---|---|---|---|
| AI disclosure | Firm discusses AI as capability or strategy | 10-K Item 1, Item 7 | keyword screen + manual coding | 100 random filings |
| Cyber incident | Material cybersecurity event | 8-K | item-based + keyword screen | all positives checked |
| Credit agreement | Loan contract disclosed | EX-10 | exhibit description contains “credit agreement” | sample vs exhibit index |
| Acquisition covenant | Clause restricting acquisitions | Loan exhibit | clause extraction | dual-coded subset |
A6. SeekEdgar workflow
A complement to EDGAR and Python, useful for exploration.
- Search phrase across filings, footnotes, MD&A, SOX 404, audit reports, CD&A.
- Limit to filing type or section.
- Inspect snippets and tables.
- Export results.
- Validate manually.
- Use as a pilot, then design programmatic extraction.
SeekEdgar is useful as an exploratory, no-code layer on top of EDGAR. For published research, still validate and document the extraction carefully.
A7. Good research question templates
- What disclosure reveals a mechanism not available in standard datasets?
- What firm behaviour is documented before market outcomes are observed?
- What contract term or governance mechanism shapes future decisions?
- What regulatory change altered how firms disclose a topic?
- What text can distinguish substantive adoption from symbolic disclosure?
A8. A starter reading list
For students who want entry points into the literatures referenced in this talk.
Surveys (start here)
- Loughran and McDonald (2016) on textual analysis.
- Edmans (2014) on blockholders.
- Yermack (2010) on shareholder voting.
Text as data
Events and disclosure
Presenter’s note on SEC textual analysis: mingze-gao.com/posts/textual-analysis-on-sec-filings.
References
Amir, Eli, Shai Levi, and Tsafrir Livne. 2018. “Do Firms Underreport Information on Cyber-Attacks? Evidence from Capital Markets.” Review of Accounting Studies 23 (3): 1177–206. https://doi.org/10.1007/s11142-018-9452-4.
Babina, Tania, Anastassia Fedyk, Alex He, and James Hodson. 2024. “Artificial Intelligence, Firm Growth, and Product Innovation.” Journal of Financial Economics 151: 103745. https://doi.org/10.1016/j.jfineco.2023.103745.
Bebchuk, Lucian, Alma Cohen, and Allen Ferrell. 2009. “What Matters in Corporate Governance?” Review of Financial Studies 22 (2): 783–827. https://doi.org/10.1093/rfs/hhn099.
Bernstein, Shai. 2015. “Does Going Public Affect Innovation?” Journal of Finance 70 (4): 1365–403. https://doi.org/10.1111/jofi.12275.
Brav, Alon, Wei Jiang, Frank Partnoy, and Randall Thomas. 2008. “Hedge Fund Activism, Corporate Governance, and Firm Performance.” Journal of Finance 63 (4): 1729–75. https://doi.org/10.1111/j.1540-6261.2008.01373.x.
Chava, Sudheer, and Michael R. Roberts. 2008. “How Does Financing Impact Investment? The Role of Debt Covenants.” Journal of Finance 63 (5): 2085–121. https://doi.org/10.1111/j.1540-6261.2008.01391.x.
Cohen, Lauren, Christopher Malloy, and Quoc Nguyen. 2020. “Lazy Prices.” Journal of Finance 75 (3): 1371–415. https://doi.org/10.1111/jofi.12885.
Edmans, Alex. 2014. “Blockholders and Corporate Governance.” Annual Review of Financial Economics 6: 23–50. https://doi.org/10.1146/annurev-financial-110613-034455.
Edmans, Alex, Vivian W. Fang, and Emanuel Zur. 2013. “The Effect of Liquidity on Governance.” Review of Financial Studies 26 (6): 1443–82. https://doi.org/10.1093/rfs/hht012.
Florackis, Chris, Christodoulos Louca, Roni Michaely, and Michael Weber. 2023. “Cybersecurity Risk.” Review of Financial Studies 36 (1): 351–407. https://doi.org/10.1093/rfs/hhac024.
Gao, Mingze, Thanh Son Luong, and Buhui Qiu. 2026. “Real Estate Collateral, Lender Screening, and M&A Performance.” Journal of Corporate Finance 98: 102962. https://doi.org/10.1016/j.jcorpfin.2026.102962.
Hassan, Tarek A., Stephan Hollander, Laurence van Lent, and Ahmed Tahoun. 2019. “Firm-Level Political Risk: Measurement and Effects.” Quarterly Journal of Economics 134 (4): 2135–202. https://doi.org/10.1093/qje/qjz021.
Hoberg, Gerard, and Gordon Phillips. 2016. “Text-Based Network Industries and Endogenous Product Differentiation.” Journal of Political Economy 124 (5): 1423–65. https://doi.org/10.1086/688176.
Lerman, Alina, and Joshua Livnat. 2010. “The New Form 8-K Disclosures.” Review of Accounting Studies 15 (4): 752–78. https://doi.org/10.1007/s11142-009-9114-7.
Li, Feng. 2008. “Annual Report Readability, Current Earnings, and Earnings Persistence.” Journal of Accounting and Economics 45 (2-3): 221–47. https://doi.org/10.1016/j.jacceco.2008.02.003.
Loughran, Tim, and Bill McDonald. 2011. “When Is a Liability Not a Liability? Textual Analysis, Dictionaries, and 10-Ks.” Journal of Finance 66 (1): 35–65. https://doi.org/10.1111/j.1540-6261.2010.01625.x.
Loughran, Tim, and Bill McDonald. 2016. “Textual Analysis in Accounting and Finance: A Survey.” Journal of Accounting Research 54 (4): 1187–230. https://doi.org/10.1111/1475-679X.12123.
Matsumura, Ella Mae, Rachna Prakash, and Sandra C. Vera-Muñoz. 2014. “Firm-Value Effects of Carbon Emissions and Carbon Disclosures.” The Accounting Review 89 (2): 695–724. https://doi.org/10.2308/accr-50629.
Nini, Greg, David C. Smith, and Amir Sufi. 2009. “Creditor Control Rights and Firm Investment Policy.” Journal of Financial Economics 92 (3): 400–420. https://doi.org/10.1016/j.jfineco.2008.04.008.
Nini, Greg, David C. Smith, and Amir Sufi. 2012. “Creditor Control Rights, Corporate Governance, and Firm Value.” Review of Financial Studies 25 (6): 1713–61. https://doi.org/10.1093/rfs/hhs007.
Patatoukas, Panos N. 2012. “Customer-Base Concentration: Implications for Firm Performance and Capital Markets.” The Accounting Review 87 (2): 363–92. https://doi.org/10.2308/accr-10198.
Roberts, Michael R., and Amir Sufi. 2009. “Control Rights and Capital Structure: An Empirical Investigation.” Journal of Finance 64 (4): 1657–95. https://doi.org/10.1111/j.1540-6261.2009.01476.x.
Sautner, Zacharias, Laurence van Lent, Grigory Vilkov, and Ruishen Zhang. 2023. “Firm-Level Climate Change Exposure.” Journal of Finance 78 (3): 1449–98. https://doi.org/10.1111/jofi.13219.
Yermack, David. 2010. “Shareholder Voting and Corporate Governance.” Annual Review of Financial Economics 2: 103–25. https://doi.org/10.1146/annurev-financial-073009-104034.
Navigating Corporate Filings